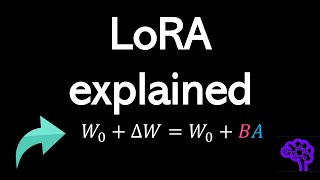LoRA explained (and a bit about precision and quantization) Share: Download MP3 Similar Tracks Quantizing LLMs - How & Why (8-Bit, 4-Bit, GGUF & More) Adam Lucek Low-rank Adaption of Large Language Models: Explaining the Key Concepts Behind LoRA Chris Alexiuk LoRA - Explained! CodeEmporium Optimize Your AI - Quantization Explained Matt Williams How might LLMs store facts | DL7 3Blue1Brown LoRA & QLoRA Fine-tuning Explained In-Depth Entry Point AI How DeepSeek Rewrote the Transformer [MLA] Welch Labs What is Low-Rank Adaptation (LoRA) | explained by the inventor Edward Hu A Helping Hand for LLMs (Retrieval Augmented Generation) - Computerphile Computerphile LLM (Parameter Efficient) Fine Tuning - Explained! CodeEmporium RAG vs. Fine Tuning IBM Technology Which Quantization Method is Right for You? (GPTQ vs. GGUF vs. AWQ) Maarten Grootendorst What is LoRA? Low-Rank Adaptation for finetuning LLMs EXPLAINED AI Coffee Break with Letitia QLoRA—How to Fine-tune an LLM on a Single GPU (w/ Python Code) Shaw Talebi Transformers (how LLMs work) explained visually | DL5 3Blue1Brown Fine-tuning LLMs with PEFT and LoRA Sam Witteveen An introduction to Policy Gradient methods - Deep Reinforcement Learning Arxiv Insights Uniform Manifold Approximation and Projection (UMAP) | Dimensionality Reduction Techniques (5/5) DeepFindr Sequence-to-Sequence (seq2seq) Encoder-Decoder Neural Networks, Clearly Explained!!! StatQuest with Josh Starmer What are Diffusion Models? Ari Seff