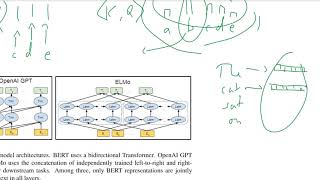
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding Share: Download MP3 Similar Tracks XLNet: Generalized Autoregressive Pretraining for Language Understanding Yannic Kilcher BERT explained: Training, Inference, BERT vs GPT/LLamA, Fine tuning, [CLS] token Umar Jamil Attention Is All You Need Yannic Kilcher GPT-2: Language Models are Unsupervised Multitask Learners Yannic Kilcher Transformers (how LLMs work) explained visually | DL5 3Blue1Brown CS480/680 Lecture 19: Attention and Transformer Networks Pascal Poupart BERT Neural Network - EXPLAINED! CodeEmporium Attention is all you need (Transformer) - Model explanation (including math), Inference and Training Umar Jamil A Hackers' Guide to Language Models Jeremy Howard Transformer Neural Networks, ChatGPT's foundation, Clearly Explained!!! StatQuest with Josh Starmer REALM: Retrieval-Augmented Language Model Pre-Training (Paper Explained) Yannic Kilcher Bert: Pre-training of Deep bidirectional Transformers for Language Understanding nPlan RoBERTa: A Robustly Optimized BERT Pretraining Approach Yannic Kilcher Live -Transformers Indepth Architecture Understanding- Attention Is All You Need Krish Naik The Narrated Transformer Language Model Jay Alammar Word dan Sentence Embedding from Scratch dengan Arsitektur BERT Manusia Setengah Chi Kuadrat Reformer: The Efficient Transformer Yannic Kilcher Visualizing transformers and attention | Talk for TNG Big Tech Day '24 Grant Sanderson Let's build GPT: from scratch, in code, spelled out. Andrej Karpathy Stochastic RNNs without Teacher-Forcing Yannic Kilcher