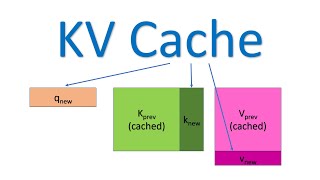
The KV Cache: Memory Usage in Transformers Share: Download MP3 Similar Tracks Rotary Positional Embeddings: Combining Absolute and Relative Efficient NLP Attention in transformers, step-by-step | DL6 3Blue1Brown Understanding the LLM Inference Workload - Mark Moyou, NVIDIA PyTorch How DeepSeek Rewrote the Transformer [MLA] Welch Labs A3C | The Asynchronous Advantage Actor Critic (A3C) architecture | A3C in Deep RL AILinkDeepTech LLM inference optimization: Architecture, KV cache and Flash attention YanAITalk A Hackers' Guide to Language Models Jeremy Howard Deep Dive into LLMs like ChatGPT Andrej Karpathy Transformers (how LLMs work) explained visually | DL5 3Blue1Brown LLaMA explained: KV-Cache, Rotary Positional Embedding, RMS Norm, Grouped Query Attention, SwiGLU Umar Jamil Visualizing transformers and attention | Talk for TNG Big Tech Day '24 Grant Sanderson The Most Accurate Speech-to-text APIs in 2025 Efficient NLP How a Transformer works at inference vs training time Niels Rogge How to make LLMs fast: KV Caching, Speculative Decoding, and Multi-Query Attention | Cursor Team Lex Clips Why Does Diffusion Work Better than Auto-Regression? Algorithmic Simplicity Goodbye RAG - Smarter CAG w/ KV Cache Optimization Discover AI Let's build the GPT Tokenizer Andrej Karpathy Quantization vs Pruning vs Distillation: Optimizing NNs for Inference Efficient NLP Fast LLM Serving with vLLM and PagedAttention Anyscale Stanford CS25: V2 I Introduction to Transformers w/ Andrej Karpathy Stanford Online